Facial recognition progress report
New algorithms have increased accuracy dramatically, but overcoming a host of variables in unconstrained settings is still the biggest challenge in facial recognition.
Identifying people in uncontrolled environments still presents the biggest challenges in facial recognition reliability, but the technology has made tremendous strides in just the past few years, according to researchers.
"Only when computers can understand face well will they begin to truly understand people's thoughts and intentions," write Cha Zhang and Zhengyou Zhang in their report for Microsoft Corporation entitled "A Survey of Recent Advances in Face Detection" (June 2010, Technical Report MSR-TR-2010-66).
Perfecting face recognition technology is dependent on being able to analyze multiple variables, including lighting, image resolution, uncontrolled illumination environments, scale, orientation (in-plane rotation), pose (out-of-plane rotation), people's expressions and gestures, aging, and occlusion (partial hiding of features by clothing, shadows, obstructions, etc.).
This is highly challenging for computer scientists. Solutions are largely mathematical, with new procedural and machine-learning algorithms being developed to improve accuracy.
"Most of the emphasis in face recognition over the past few years has been matching still frontal faces under controlled illumination," says P. Jonathon Phillips, electronics engineer with the National Institute of Standards and Technology (NIST, Gaithersburg, MD). "The release of the Multiple Biometric Evaluation 2010 report showed excellent performance on mug shots and mobile studio environments. The top performer had a match rate of 93 percent when searching a database of 1.6 million faces."
Researchers are also looking at ways to apply the latest advances in facial-recognition technology to uncontrolled environments, where success rates are 50 percent or lower. Improving success rates in video and film (Figure 1) is especially important for law enforcement (for example, reviewing security tapes for suspects). In fact, because of the possibility of riots, Scotland Yard is considering using facial-recognition technology during London's 2012 Olympic Games.

Figure 1. Some video observations of a particular face may capture transient facial features caused by changes in facial expression, momentary head rotation, intermittent occlusions or image noise. Through the University of Notre Dame's "questionable observer" detection algorithm, these observations are clustered in order to identify people who show up in an unusual number of scenes. (Univ. of Notre Dame)
Face recognition is not just for government operations -- it is also highly popular with the public, especially for social networking sites. Face-detection programs in digital photo-management software are used to tag photos and organize photo collections. Most digital cameras today have built-in face detectors that improve auto-focusing and auto-exposure.
"There are also prototypes of applications that use the built-in camera in your mobile phone," indicates Robert Frischholz, CTO and co-founder of BioID, a multimodal biometric security provider in Nuernberg, Germany. "After taking a snapshot of the crowd, for example, the application searches all available social networks to identify faces. If matches are located, that profile information can then be displayed almost in real time while you're walking down the street."

Figure 2. Three-dimensional data points from a face vastly improve the precision of facial recognition. (Univ. of Notre Dame)
Recent Advances
3D facial recognition technology is one of the best ways to neutralize environmental conditions that complicate human recognition and stump traditional face-recognition algorithms (Figure 2).
Traditional methods rely on photos for facial data-2D information. Using three-dimensional data points from a face vastly improves the precision of facial recognition. The European 3D Face Project (www.3dface.org) has shown that combining 2D data (texture, color) with 3D data (shape) results in more accurate results compared to just using 2D or 3D information alone. For example, researchers at Interval Research Corporation in Palo Alto have created a visual person tracking system by integrating depth estimation, color segmentation, and intensity pattern classification modules.
"With each modality alone it is possible to track a user under optimal conditions, but each also has substantial failure modes in unconstrained environments," indicates Trevor Darrell of Interval Research Corporation. "Fortunately these failure modes are often independent, and by combining modules in simple ways we can build a system that is relatively robust . . . [and] responds to a user's face in real-time." When all modules are functioning together the overall success rate is 96 percent or higher.
"Using 'morphable models' to produce multiple synthetic views of a face, from different poses and/or lighting, from an original real image, and then using these views for matching, is a significant technical advance," adds Kevin W. Bowyer, chair of the Department of Computer Science and Engineering at the University of Notre Dame. "This is related to the idea that pose, illumination, and expression are three important dimensions of variation in facial images that contribute to making face recognition a difficult problem." Multiple images are integrated to form a final 3D shape that matches the face as closely as possible-this final image significantly improves accuracy when comparing oriented facial images of the same person.
3D research is enhanced by the development of sophisticated sensors that do a better job of capturing 3D face imagery. The sensors work by projecting structured light onto the face. Up to a dozen or more of these image sensors can be placed on the same CMOS chip-each sensor captures a different part of the spectrum. According to Aptina Imaging, an image sensor manufacturer in San Jose, California, arrays of light-sensitive pixels (photodiodes) gather photons and convert them to visible images. The sensors use multiple transistors to amplify and move the charge provided by the incoming photons, enabling the pixels to be read individually. Both the photodetector and the readout amplifier in CMOS sensors are part of each pixel, allowing the integrated charge to be converted into a voltage inside the pixel. Aptina's 3.1-megapixel surveillance sensor is a good example of what's new in the market: HD video of up to 1080p at 60 fps, a wide dynamic range capability, adaptive local tone mapping, and advanced binning techniques that enable the sensor's sub 1-lux low-light performance.
Unconstrained Settings
Face detection in completely unconstrained settings remains highly challenging because of the host of variables that must be overcome. "In our in-house tests, state-of-the-art face detectors can achieve about 50-70 percent detection rate, with about 0.5-3 percent of the detected faces being false positives," indicates Zhang and Zhang. "Consequently, there is still a lot of work that can be done to improve the performance, especially regarding the learning algorithm and features."
Video, of course, is a highly unconstrained setting. Bowyer and his team have developed an unsupervised classification algorithm for detecting questionable observers that begins by merging face image sequences (face tracks) that correspond to the same individual in a particular video. "We then remove outlying face images from the merged face tracks based on the observations that certain head poses and facial expressions are more likely than others," he says. "This reduces the influence of unrepresentative data and increases the homogeneity of the sampling encompassed by an individual face track."
The detection algorithm subsequently clusters the face tracks, ideally placing all of the face tracks that represent a particular individual in the same cluster and creating a distinct cluster for every individual. If a cluster contains face tracks from more than a specified number of videos, the detection algorithm outputs all of its images for review.
Infrared Light
Images currently used for facial recognition are typically taken in visible light. Research is showing that infrared and near-infrared images can also be effective; other data types, such as terahertz, are also being tested. The Machine Vision Laboratory at University of the West of England in Bristol is using near-infrared and visible light to identify faces. Mark Hansen's research team has created a system of 3D face capture and processing using photometric stereo (PS) hardware and algorithms. The high-speed 3D data capture system can capture four raw images in approximately 20 ms.
"The device can operate with either visible light or near-infrared (NIR) light," says Hansen. "NIR light sources offer the advantages of being less intrusive and more covert than most existing face recognition methods. Furthermore, our experiments show that the accuracy of the reconstructions is also better using NIR light."
A modified four-source PS algorithm enhances the surface normal estimates by assigning a likelihood measure for each pixel being in a shadowed region, which is determined by discrepancies between measured pixel brightness and expected values. "Where the likelihood of shadow is high, then one light source is omitted from the computation for that pixel; otherwise a weighted combination of pixels is used to determine the surface normal," Hansen adds. "Therefore the precise shadow boundary is not required."
Challenges Ahead
"The biggest technology challenges that remain in facial identification technology are overcoming low-resolution facial images, occlusion, orientation (being able to recognize equally profiles and frontal face), and orientation age -- mainly very young and very old," says Claude Bauzou, product manager for Morpho's Facial Recognition Solutions in Issy-les-Moulineaux, France.
These challenges are being approached from many directions. MIT, for example, is researching multidimensional morphable models, view-based human face detection, cortex-like mechanisms, and object detection by components. Other scientists are working on new algorithms, statistical pattern recognition, illumination cone models, geometrical face models, and slow feature analysis.
Yet others are going against conventional wisdom by focusing on sparse partial representation -- the idea that the choice of features is less important than the number of features used. Scientists at the University of Illinois and University of California, Berkeley have developed a sophisticated face-recognition system based on sparse representation that is remarkably accurate in real-life situations.
Existing technologies try to find optimal facial features to use as key identifiers -- for example, the width of the nose. Rather than seeking individual features, this system's sparse representation algorithm randomly selects pixels from all over the face, increasing the accuracy of recognition even in cases of occlusion, varying expressions, or poor image quality.
"New mathematical models have allowed researchers to identify faces so occluded that it was previously thought impossible," says University of Illinois lead researcher Dr. Yi Ma.
Ma's algorithm increases accuracy by ignoring all but the most compelling match from one subject. When applied to the Yale B database of images, this system showed 98.3 percent accuracy using mouth-region images; for the AR database it scored 97.5 percent accuracy for face images with sunglasses and 93.5 percent for a scarf disguise.
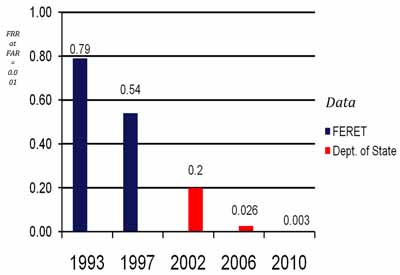
Figure 3. U.S. Government-sponsored evaluations and challenge problems have helped spur over two orders-of-magnitude improvement in face-recognition system performance. Since 1993, the error rate of automatic face-recognition systems has decreased by a factor of 272. The reduction applies to systems that match people with face images captured in studio or mugshot environments. In Moore's law terms, the error rate decreased by one-half every two years.
Progress is quantified from the 1993 evaluations to MBE 2010. Improvement is reported at five key milestones. For each milestone, the false rejection rate (FRR) at a false acceptance rate (FAR) of 0.001 (1 in 1,000) is given for a representative state-of-the-art algorithm. For each milestone, the year and evaluation are provided. Beginning with the FRVT 2002, the evaluations switched to a benchmark dataset provided by the US Department of State (DoS), which is comparable to the FERET dataset. (Image courtesy of Jonathon Phillips, NIST)
Mark Crawford is a freelance science writer based in Madison, Wisconsin.


